国家、京东、百度都在做同一件事:解决具身智能的数据问题!而数据,才是具身智能基础设施的竞争焦点
国家、京东、百度都在做同一件事:为具身智能“喂”数据
2026年4月到5月,具身智能领域发生了几件看起来独立、但指向同一个方向的事。
4月29日,国家数据发展研究院联合北京市政务服务和数据管理局,以及银河通用、石景山人形机器人数据训练中心、光轮智能等企业,发起了“具身智能数据推进计划(北京)”。

4月16日,京东在具身智能生态发布会上宣布,自研超高清采集终端JoyEgoCam,开放2000小时高精标注数据集,计划发动60万人参与数据采集,两年内积累1000万小时真实场景视频数据。

4月10日,百度智能云联合零次方、灵生科技、傅利叶等企业,推出“具身智能数据超市(Beta版)”,为数据生产方提供交易渠道。

这三件事的共同关键词是:数据。
一、国家数研院的推进计划:
解决数据“怎么采、怎么用、怎么流通”
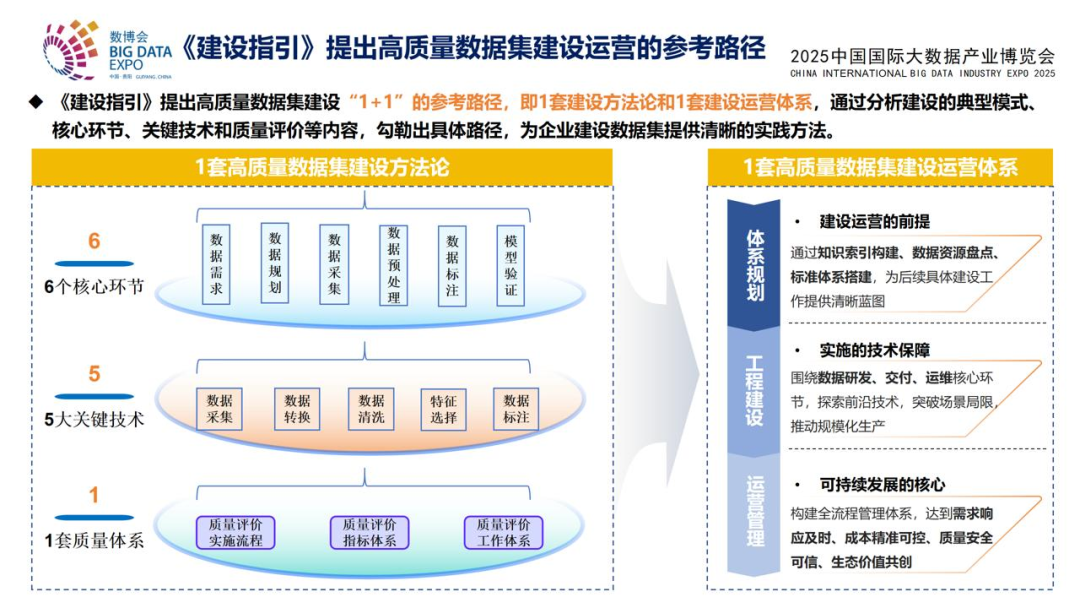
国家数据发展研究院的推进计划,采取了“北京先行先试、全域辐射带动”的梯次推进思路。具体要做四件事:
第一,制定标准。绘制高价值应用场景图谱,构建“国标—行标—地标—团标”的标准矩阵。
第二,建设数据赋能工场。开发全流程数据开发利用工具链。
第三,汇聚产业链企业,联合攻关数据权属相关机制。
第四,参与国际标准制定。
在此之前
2026年1月北京发布的《北京人工智能创新高地建设行动计划》已经明确提出“以数赋模”,要强化具身智能数据集、科学智能数据集和各行业高质量数据集供给。
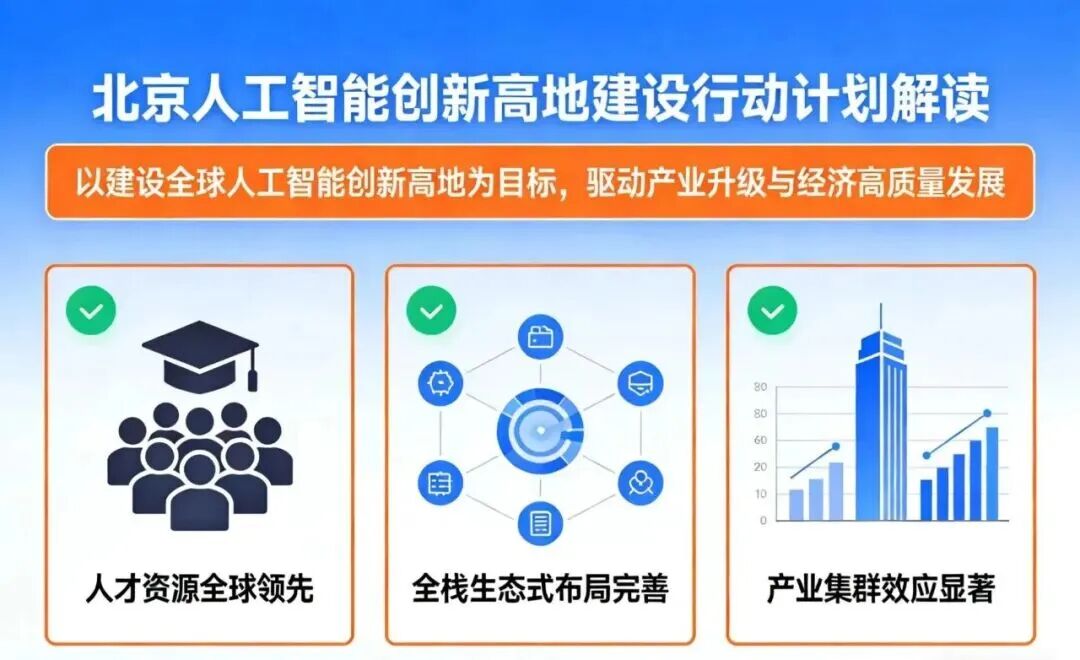
2026年4月底,《人形机器人数据集》ISO国际标准成功立项,这是具身智能领域全球首项国际标准,由北京机械工业自动化研究所有限公司牵头,覆盖数据集从规划到退役的全流程。
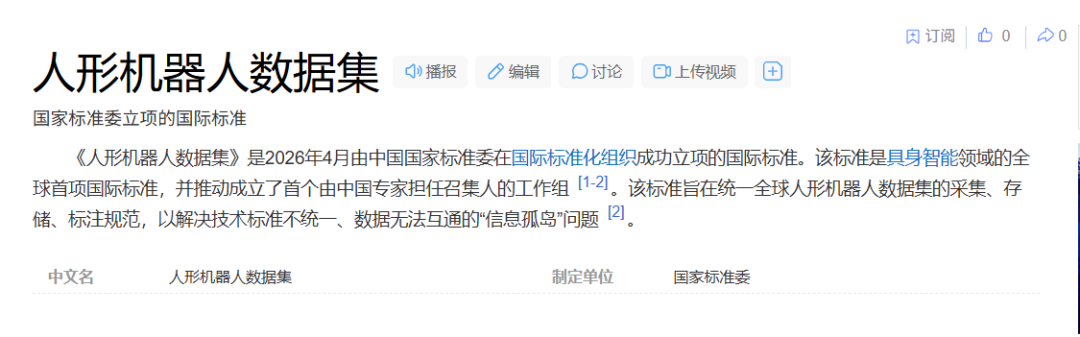
2026年初,工信部也发布了《人形机器人与具身智能标准体系(2026版)》。

这些政策和标准的工作,指向同一个问题:具身智能的数据目前缺乏统一格式和流通规则,各家采集的数据无法互通,也难以用于跨场景训练。国家数研院的推进计划就是要在北京先形成一套可执行的方案。
二、京东的计划:
60万人采集1000万小时数据
京东的布局有两个特点。
第一,数据采集规模大。
计划两年内积累1000万小时人类真实场景视频数据,发动最多60万人参与。采集设备是自研的可穿戴超高清采集终端JoyEgoCam,重220克,4K摄像头,60帧帧率,130度超广角。
第二,覆盖全链条。
京东提出了“采、存、标、训、评、仿、测”全链路的数据基础设施,包括自研的具身大模型JoyAI-RA,以及具身智能数据交易平台。通过AI数据湖平台和JoyBuilder仿真平台,将原始数据转化为标准训练集,模型训练效率提升了3.5倍。
京东的场景优势在于零售、物流、工业、健康等业务,天然能产生大量真实操作画面。
这些数据如果采集和标注到位,可以直接用于训练机器人在真实商业环境中的操作能力。
三、百度的数据超市:
以中立平台促进行业流通
百度智能云的“具身智能数据超市(Beta版)”,定位是一个交易平台。
百度智能云泛科技行业负责人在发布时提到,很多企业已经采集了大量数据,但不知道怎么做数据售卖。
百度以中立的第三方身份搭建平台,为数据生产方增加变现渠道,同时通过市场机制验证什么样的数据是行业真正需要的。
平台采用层级化、可扩展的数据标签体系,通过原子标签的标准化定义与复合标签的结构化组合,让数据集的属性更容易识别。

具身数据更像是制造业,需要用大量的人和机器产生大量的数据。百度搭建的这样一个平台,能够统筹资源,把整体效率拉上去,成本降下来。
目前百度智能云已为智元机器人、宇树科技等超过30家具身智能企业提供服务。
四、为什么现在大家都在做数据?
一个现实原因是:高质量真实交互数据严重不足。
据行业讨论中引用的数字,目前可用的人形机器人原始数据约50万小时(该数据为行业估计值,非官方统计)。 但这些数据是否标准化、是否合规交易、是否能跨场景复用,都还是问题。
没有足够的数据,模型训练就无从谈起。
另一个原因是,具身智能正在从实验室走向真实场景。
2026年3月,小米的人形机器人进驻北京亦庄汽车工厂压铸车间,承担自攻螺母安装任务。
连续自主运行3小时,双侧同步安装成功率达90.2%,匹配了76秒/台的产线节拍。
小米计划2026年部署超过2000台人形机器人,2027年产能达到10万台,目标任务成功率超99%、无故障时间突破1万小时。

X Square Robot发布了基于世界统一模型架构的具身智能基础模型WALL-B,计划在35天内首次在真实家庭场景部署通用机器人。
它石智航发布了通用具身大模型AWE3.0,在AWE展会上完成了超百次亚毫米级线束装配。

但这些落地应用都依赖大量真实场景数据。
工厂产线的操作数据、家庭环境的行为数据、工业装配的精细动作数据,每增加一个场景,就需要重新采集或适配一批数据。
标准化的数据采集、标注、交易体系,成为制约行业发展的瓶颈。
五、目前的数据基础设施
走到哪一步了?
从2026年初到5月,可以观察到几条线同时推进:
标准线:工信部发布《人形机器人与具身智能标准体系(2026版)》,ISO《人形机器人数据集》国际标准立项。
政策线:北京提出“以数赋模”,国家数研院发起推进计划。
企业线:京东启动大规模数据采集,百度上线数据交易平台,帕西尼等企业也上线了多模态触觉视觉数据集。
但也要看到,这些工作大多刚刚起步。
京东的1000万小时数据计划需要两年,国家数研院的推进计划还在“发起”阶段,百度的数据超市还是Beta版。
如果把具身智能比作一棵树,算法是枝叶,硬件是树干,那么数据就是根系。
根系扎不深、分布不广,树就长不大。

2026年4月前后发生的这几件事——国家数研院推进计划、京东启动大规模采集、百度搭建交易平台——本质上都是在做同一件事:
为这棵树的根系松土、施肥、修渠。
它们解决的不是某个具体的算法突破,而是整个行业最底层、最基础的问题:数据从哪里来,以什么标准来,来了之后怎么用,用完之后怎么流通。
中国在具身智能数据基础设施上的这轮布局其意义可能不亚于当年在高性能计算、互联网骨干网上的投入。
因为一旦形成统一标准、规模采集、合规流通的闭环,中国就有机会在全球具身智能竞争中,建立起一个基于数据规模和数据治理能力的结构性优势。
这个优势不像单点技术突破那样引人注目,但它更持久,也更难被复制。
当然,计划毕竟只是计划。京东的1000万小时数据能否如期完成,百度的数据超市能否跑通商业模式,国家数研院的标准能否被全行业接受,都需要时间检验。
从这个角度看,2026年的这个春天,或许只是漫长过程中的一个普通节点。但它标记了一个事实:中国具身智能产业,正在从“做出来看看”转向“做出来用用”。
而数据,是这场转向最沉默也最关键的推动力。