数采工厂最新产业格局,数据定义权的终极争夺

机器人也得“上学”?一场关乎“物理常识”的豪赌
作者:余柯、赵鹏程
编辑:晋芳博
前言
如果把人形机器人比作一个刚出生的婴儿,那么现在的 AI 大模型就是它的“大脑”。但问题来了:一个只有大脑、没有生活经验的婴儿,能直接去工厂打螺丝或者在家里收衣服吗?
答案是:不能。
过去一年,具身智能最火的词不是“本体”,而是“数据”。不同于大语言模型可以靠抓取互联网文本来“刷题”,机器人要学会在现实世界里干活,必须拥有“物理常识”——捏碎一个鸡蛋和抓起一个钢球,力道有何区别?地毯上的摩擦力和瓷砖地有什么不同?
这些微妙的、不可言说的“手感”,只能在真实的物理世界里一遍遍“刷经验”。而这一核心需求,也直接推动了数采工厂的快速崛起与迭代——从2024年行业开始聚焦数采需求,到2026年目前形成的64座数采工厂规模(目前还在持续更新中),短短两年时间,数采工厂不仅完成了数量上的扩张,更在技术路线、产业格局上发生了深刻变化。
本文将从梳理视角,为大家呈现数采工厂的发展脉络、当前格局与产业现状,传递行业最新动态。

核心要点
· 产业基建: 27 城 54 座数采工厂全国布局
· 核心技术:帕西尼感知解锁物理常识
· 产业争夺:抢占具身智能数据定义权
01
技术演进:从“影子训练”到“穿戴设备”的跨越
如果把机器人的数据积累比作“攒经验升级”,那么早期的仿真数据,就像是纸上谈兵的“理论知识”,而真实的物理交互数据,才是能真正提升“战斗力”的“实战经验”——前者是基础铺垫,后者才是核心关键。
早期,整个行业几乎都在押注仿真数据,试图在虚拟空间里教机器人干活、积累经验。但大家很快发现,再逼真的虚拟场景,也无法复现物理接触中那些微妙的摩擦力与形变——机器人在虚拟世界里能完美抓起鸡蛋,到了现实中可能一捏就碎。

直到2026年,行业终于达成共识:真实的“物理经验”,才是机器人实现质的升级的关键。
目前,行业内核心数采路径主要分为三类,每一类都对应着机器人“学习”的不同阶段:
1. 视觉数据:机器人的“基础感知工具”,能让它快速识别物体、判断周围环境,比如看清眼前是易碎的鸡蛋还是坚硬的钢球,是光滑的瓷砖还是粗糙的地毯,为后续的精准操作提供重要前提。
2. 遥操作:“手把手”的示教模式,就像是“老师手把手教学生”,工作人员通过远程控制,亲自示范精细动作,让机器人精准模仿,确保每一个操作都到位、不失误,为机器人积累基础操作经验。
3. 可穿戴设备:破解数据瓶颈的核心路径,从2024年5月起,以 UMI(通用操作接口)、外骨骼、动捕服为代表的设备开始大规模进入实战场。工作人员戴上这些带有传感器的设备,自己完整做一遍操作动作,机器人就能像素级同步这份“手感”和力反馈,这也是目前破解“数据瓶颈”最核心、最有效的办法。
02
全国数采地图格局拆解
截至目前,中国拟建成64 座(目前还在持续更新中)具身智能数采中心、创新中心和训练场,分布在包括北京、上海、深圳、武汉、杭州、成都在内的多个城市。

(上下滑动查看更多)
可能有读者会好奇,这些数采工厂看似大同小异,实则背后有着截然不同的运营逻辑,目前行业已明确分化出三类核心流派。
1.自建自用:技术派的“闭环试验场”
这类工厂由深耕具身智能大脑研究的头部企业运营,核心逻辑十分清晰 —— 作为具身智能大脑的研发主体,企业深知机器人本体的质量直接决定真机数据的采集质量,而高质量物理交互数据,正是训练、优化具身智能大脑的核心支撑。
自建工厂、自主采数,才能形成 “硬件载体 - 高质量数据 - 大脑模型” 的完整闭环,让具身智能大脑实现高效迭代。
· 星海图:以具身智能大脑研究为核心方向,提出 “一脑多形” 的研发理念,其所有布局均围绕打造通用化的具身智能大脑展开。

为给大脑积累足够的真实开放场景预训练数据,星海图并未将机器人局限在实验室,而是把数十台 R1 系列机器人投放到酒店、食堂、商场等实际场景,让机器人一边完成实操任务一边采集数据。
在其看来,这类真实场景的物理交互数据,是训练具身智能大脑、提升其场景泛化能力与物理常识理解能力的关键,数据采集本身就是大脑研发的重要生产环节。
· 千寻智能:核心聚焦具身智能大脑的研发与落地,是兼具大脑模型与机器人本体研发能力的全栈公司,其自研硬件的初衷,就是为旗下具身智能大脑的研发,采集更高质量、更贴合真实场景的真机交互数据 “燃料”。

也正因此,千寻智能全力扩张自建数据工厂,规模已接近千人,打造专属的具身智能大脑训练数据试验场,通过硬件与数据的深度协同,为大脑模型的快速迭代、能力升级提供核心支撑。
2. 政府共建:以“场景 + 数据”为筹码的产业闭环
这类模式的核心,就是政府拿“场景+政策”当筹码,企业拿“技术+数据”来配合,最终实现“政府搭台、企业唱戏、数据赋能”的良性闭环,既能助力本地产业升级,也能吸引更多相关企业落地扎根。
· 北京亦庄: 打造全国首个具身智能机器人全栈式开发者社区。通过每年发放 1 亿元“数据券”,引导企业采购数据集、数据接口等产品,将单位数据采集成本降低 50%——这既有效降低了企业的运营负担,也让本地的数采生态变得越来越完善。
· 上海国地共建:由上海市经信委、浦东新区政府共同指导,国家地方共建人形机器人创新中心(国地中心)牵头建设的全国首个异构人形机器人训练场于 2025 年 1 月在浦东张江正式启用,是典型的 “政府引导 + 国家级平台 + 市场运作” 国地共建模式。

该训练场占地 5000 平方米,首期部署超 100 台异构人形机器人,以 10 余种典型场景开展数据采集与模型训练,预计年内完成 500 万条真机数据采集,目标成为全球最大的具身智能数据池。
这种模式不仅为上海吸引了智元、傅利叶等头部企业集聚,更通过数据标准化与大模型研发,提升了上海在具身智能领域的产业话语权与招商吸引力。
3. 场景倒逼,特色产业驱动的超级工厂
这一类工厂多落地在拥有特定优势产业的中小型城市,核心逻辑是“场景即资产”——这些城市的特色产业,恰恰是机器人最需要的真实实操场景,场景方的实际需求,直接倒逼了数采工厂的落地和发展。
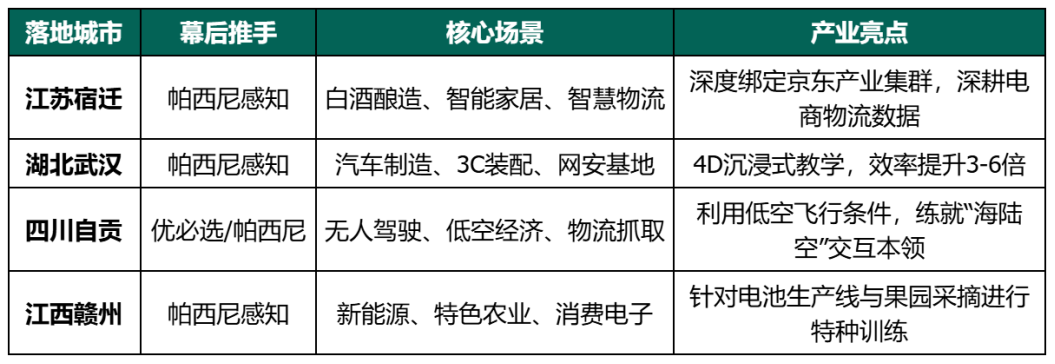
· 江苏宿迁:结合京东集团的物流集群,深耕白酒酿造、智慧物流等场景。帕西尼在宿迁投建万平米基地,正是依托其核心的帕西尼感知技术,专门采集白酒装卸这类对“力控”要求极高的特定数据——白酒易碎、力道控制难度大,这种场景的数据,正是机器人提升实操能力的关键。
· 四川自贡: 依托当地良好的空域条件与低空经济、无人机产业,自贡数采中心专门采集无人机维保、复杂地形交互数据,打造“前店后厂”的区域协同模式。当地的低空产业优势,让这里成为无人机相关数据采集的天然场景,也让自贡在数采布局中占据了独特优势。
· 江西赣州: 瞄准新能源电池产线与南方特色农业,导入全身数采方案,承接特种采摘与精密电子装配的训练任务。新能源和特色农业的场景需求,倒逼数采技术针对性落地,也让赣州成为细分场景数采的重要阵地。
大家可能会好奇,为什么宿迁、自贡、赣州这些城市也能分到一杯羹?这背后是具身智能选址逻辑的深度演变:场景即资产,比起一线城市的资源优势,二三线、三四线城市的特色产业场景,反而更能提供机器人所需的真实实操数据,这也是它们能在数采布局中脱颖而出的核心原因。
从下面的表格可以看出,二三线、三四线城市拥有极为丰富的机器人实操场景,例如江苏宿迁的京东产业集群、江西赣州的新能源产线、四川自贡的低空经济,他们都是未来机器人落地应用最真实的场景:
03
从工厂扩张到产业卡位,数采格局的两年演变
如果说 2024 年是数采工厂的 “概念元年”,2025 年是 “落地扩张年”,那么 2026 年已进入 “数据主权争夺年”。
短短两年,数采工厂已从单一 “数据采集基地” 的业态,升级为具身智能产业的核心基础设施与区域竞争的战略支点,从 “有没有” 快速走向 “优不优、全不全、标不标准” 的新阶段。

当下,“数据定义权” 已不再是企业之间的单打独斗,而是上升为区域产业战略。对各地而言,谁能率先建成高质量、标准化、规模化的数据底座,谁就能吸引具身智能上下游产业链集聚,制定行业标准,主导产业生态,这也是各地争相布局数采工厂的核心原因。
但随之而来的,是行业马太效应的凸显:数据资源正快速向头部企业集中,“数据垄断” 的雏形已初步显现。头部企业凭借资金、技术和场景优势,掌控着优质的真机数据和全链路生态,这让中小企业及后进入者的准入门槛急剧抬高,未来想要在数采领域分一杯羹,难度将大幅增加。
04
结语:
如果说 2024 年行业还在讨论“有没有数据”,2025 年在比拼“谁的数据更多”,那么到了 2026 年,一个残酷的分水岭已经出现:数采工厂的竞争,早已跳出“数量竞赛”,进入“体系比拼”的终极阶段——谁能把碎片化的真机数据,打磨成标准化、全链路的体系化基础设施,谁才能站稳脚跟,真正参与具身智能下一阶段的产业决战。
如今,数采工厂的建设和扩张已在全国铺开,数据定义权的争夺从企业延伸至区域,头部集聚的马太效应愈发明显。当这些数采工厂年产出数十亿条高质量真机数据,当Scaling Law在物理世界再次显灵,这场关乎具身智能未来、关乎产业格局重构、关乎数据主权的豪赌,才刚刚拉开真正的序幕。