国家重磅出手!数据也要进交易所了!从“小散乱”到“挂牌上市”,高质量数据集明确部署可挂牌交易
就在3月24日,国新办的一场发布会上,国家数据局局长刘烈宏给出了一个让人眼前一亮的答案——让高质量数据集像股票一样,挂牌、上架、交易。你没看错,数据也要进交易所了。
这背后,是一场正在悄然改变中国AI产业格局的“数据供给侧改革”。

核心就围绕“高质量数据集”做了明确部署,没有多余的空话,每一句都藏着行业风口。
局长刘烈宏在发布会上强调,2026年是数据要素价值释放年,重中之重就是推动高质量数据集市场化、价值化,让数据要素跑出“加速度”。

最关键的一点,就是明确要推动行业高质量数据集在数据交易所挂牌、上架、交易,还会支持数据商、流通服务平台提供配套服务,鼓励大家探索多样化的流通模式,让供需双方精准对接。
除此之外,发布会还透露了一组震撼数据:
截至2025年底,我国已建成的高质量数据集超过10万个,总体量超890PB,相当于中国国家图书馆数字资源总量的310倍,可见数据资源的“家底”有多厚。
另外,国家还会持续推进数据赋能人工智能发展,提出“人工智能发展到哪里,高质量数据集就建设到哪里”,同步实施六大专项行动,打造能直接支撑AI研发的高质量数据集,这也意味着,高质量数据集的需求会越来越大。
02 什么是“高质量数据集”?
不是所有数据都能卖
很多人可能会疑惑,平时我们产生的聊天记录、浏览痕迹,算不算能交易的高质量数据集?
答案是:当然不算。
所谓高质量数据集,核心是“能用、有用、合规”,不是随便拼凑的零散数据,这也是它能挂牌交易的关键。
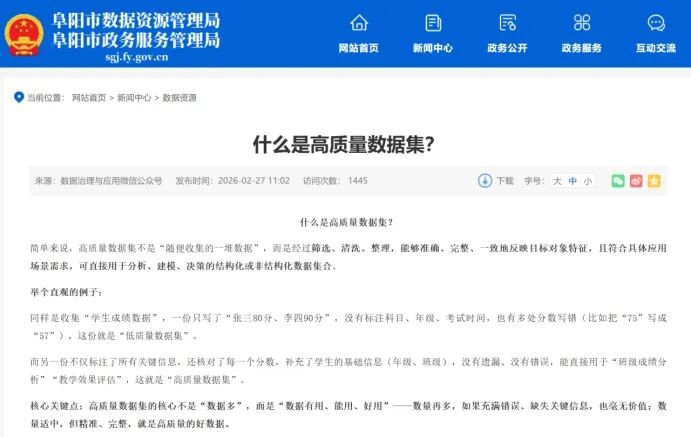
结合国家数据局的定义和全网案例来看,高质量数据集要满足三个核心条件:
一是真实场景产生,不是人工编造的;
二是结构完整,能直接被企业、机构拿来使用,不用再花大量时间整理;
三是经过合规验证,做好脱敏处理,不泄露个人隐私和商业秘密。
比如成都近期成交的车路协同数据集,覆盖真实交通场景,包含流量、车辆行为等核心信息,能直接用于自动驾驶研发,这就是典型的高质量数据集。
而且国家也在主动搭建保障体系,比如布局了成都、沈阳等7个数据标注先行先试城市,出台相关实施意见,遴选优秀案例,就是为了让高质量数据集的建设、加工更规范,确保每一个挂牌交易的数据集,都符合安全合规要求。
03 已经有人靠高质量数据集赚钱了?
光说不练假把式。实际上,高质量数据集的挂牌交易已经实实在在落地了。
今年3月,北京无限迭代科技的高质量数据集在北京国际大数据交易所完成全流程交易,其“大模型训练专用试题”系列所有题目都精准标注为“hard”高难度标签。
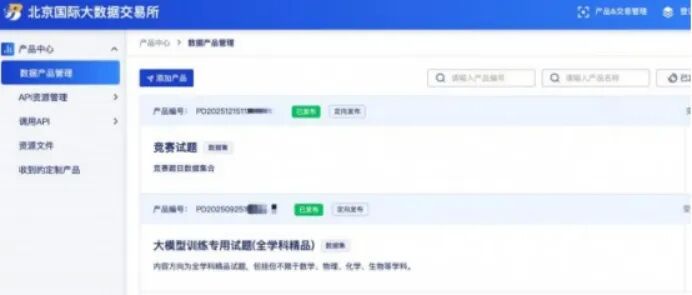
同月,成都两款数据产品——车路协同感知源数据集和具身智能机器人工况数据集——在成都文化产权交易所挂牌成交,仅耗时一个多月。
医疗领域也传来捷报,无锡“去标识化医疗影像数据集”和“慢性疾病综合数据集”在江苏省数据交易所完成交易,可用于医学影像AI建模等场景。
成都文交所数据治理技术介绍用图
04 10万个数据集,够不够AI“吃”?
先来看一组让人心跳加速的数字。
截至2025年年底,全国已经建成的高质量数据集超过了10万个,总体量超过890PB。890PB是什么概念?
这相当于中国国家图书馆数字资源总量的310倍。
换句话说,如果把国家图书馆的全部数字资源比作一本书,那现在已有的高质量数据集,相当于整整310座图书馆的藏书量。
刘烈宏在发布会上说得很直白:“日均Token调用量的大量增加,充分表明中国的人工智能发展进入了快速增长阶段。”
从能跟你聊天的对话机器人,到能帮你做决策的智能体,中国AI正在完成一次质的飞跃。而支撑这场飞跃的,正是那10万个高质量数据集。
05 当数据成为“硬通货”
从某种意义上说,高质量数据集挂牌交易,标志着一个新时代的开始。
在这个时代里,数据不再只是企业的内部资产,而是可以流通、可以定价、可以交易的“硬通货”。
这对AI创业者来说是好事——不用再为找不到好数据发愁,去交易所“淘”就行。对数据持有者来说也是好事——手里的数据不再是“沉睡的资产”,而是能变现的“宝藏”。
对整个AI产业来说更是好事——当数据的供给变得充足、规范、高质量,AI的发展才能真正跑出加速度。